Tech
Why it is necessary and urgent to get rid of Google and how to start doing it
(We resume the open speech with Strong love, body not: that on the capitalism of large platforms, on the behaviors induced by the algorithms of social media, on the extraction of big data of our lives and the ubiquitous surveillance that accompanies it.
Do it right in the days ofCovid Emergency 19.
Among the powers and economic subjects which profit from the epidemic or better, measures of social distancing and new regulation of the social body, there are especially the multinationals of Big Tech. They take advantage of this to strengthen their grip on society, their de facto monopoly on many activities that are essential today. They take advantage of this to intensify the processes privatization of the public sphere.
Privatization soft, implicit and not perceived because it is not fast and "molar", there is no public conflict between the authorities (privatization vs privatization not); instead of gradual and "molecular", it occurs thanks to the thickening of networks made up of small practices and daily automatisms.
Google, which we cover in the post below, has offered to our Ministry of Education (MIUR), like those of other countries, the solution to close schools: the giant of Mountain View provides teachers email with unlimited space and platforms for telematics education (G Suite for education). Even before this announcement, several schools were pushing teachers to get the mailbox and Gmail account on Hangouts Meet and / or Google Classroom. In addition: several teachers, exasperated by the uncertainty and the impossibility of taking lessons, so as not to leave their schoolchildren and students in disarray, used these tools on their own initiative, to start the lesson. ;Distance Learning.
If on the one hand we admire the intention and how they say it today resistance of these teachers, on the other hand, we find that there is no awareness of what they are doing really these instruments, the functioning of which we see only the idiomatic tip of the iceberg.
In practice, public school privatize the same teacher-student relationship, encouraging both private and non-privacy platforms, which will store new data and then sell it to a variety of subjects, which will not only be used for commercial purposes, but also Politics, in all possible meanings of the term. And in all of this, Google / Alphabet will also pass for a benefactor: the company that saved the school.
Google finds in this emergency that however it helps to feed in different ways the possibility of becoming innervated in more and more lymph nodes of the associated life, making it essential even if the alternatives are there. They are great, and they would also be easy to use.
Anyone who does not consider the word democracy as a simple envelope containing only rhetoric, once well informed * of what Google is and its benefits, can only draw a conclusion: Google is a threat to democracy .
state of emergency not the epidemic itself but the emergency like government method based on epidemic he pushes us backwards on so many grounds that we don't know where to start to signal the consequences, to explain who and how he catches the ball.
In the end, one starting point is worth the other. As parents, we start from school, distance learning and, in particular, from Google.
Before the virus, we asked the giapster Ca_Gi write a song for Giap on the phenomenon of degoogling, which was spreading rapidly in late 2019. With the coronavirus emergency, the road has gotten steeper, but that's all the more reason to go.
Good reading. WM)
of Ca_Gi.*
1. A day in your life (Google knows it)
You wake up after six hours of sleep. You slept badly, a light, restless sleep. Google knows it: it detected it from the accelerometer and microphone of your smartphone.
From the analysis of the network to which you are connected, he also knows that you were not at home, but in an apartment on the other side of the city and, according to the register of your travels, he also knows that for about a month you have been going there at least a few times a week.
Google knows who lives in this house because the GPS on your smartphone indicates its presence daily. He knows this person well, as he knows you. He knows that he is not part of your circle of close friends, because his number is not in their address books and very rarely in the same places they frequent . He knows that you registered in the address book a few months ago, but it was only in the last three that you started calling each other often.
Last night, you saw a movie on the Chromecast. Obviously, Google knows what the film was and since the GPS data indicates that you were both at home and that you did not move, this infers that you were probably in the living room.
He also knows that the other person was not very interested in the film, because while you were watching it, he was only playing a video game on his Android smartphone.
Thanks to the DNS, Google knows that as soon as you get up, like every morning, you consult the news on the usual site. Android and Chrome confirm this.
From the archives of your reading habits over the past few years, Google knows that you are interested in news relating to the housing trades, but that you only read in detail those that speak of evictions. By analyzing the texts of your emails, you know that you are also talking about them with friends and acquaintances and that you are more and more worried about the statements of a certain evaluator. By analyzing the movements of your finger on the screen, he knows which titles caught your attention even if you have not read them, and thinks if there were certain words in these titles , the likelihood of you opening them would have been greater.
At eight o'clock you have traveled a certain distance in the city. Google knows this, still thanks to GPS and because of the detachment of Wi-Fi from the apartment.
From the analysis of the route and the speed, Google deduces that the movement took place by bicycle. He knows that you then entered a certain bar, probably to have breakfast, since you stayed there for half an hour, and that you connected to Wifi by confusing the captcha three times, deducing that perhaps you're still a little sleepy, since usually catch them the first time.
Google notes that you then connected to the library network and looked for a certain object which, in your opinion, should interest you, because the research led you to turn several sites, ending up finding it on that of a certain online store where you bought it. provide your usual credit card. It is statistically likely that it could be a gift for one of your best friends, the one who will be turning years in a few weeks and who in turn often buys items with a similar style.
Then write a text on an application that you have downloaded from the Play Store and even if it is not a Google application, the company has access to the Android keyboard and therefore in any case able to understand what that you typed, including the deleted parts. The text contains passages in English and the speed with which you typed them, it understands that a language that you think you master well, even if in reality it is known that you repeat the same grammar mistakes over and over.
At this point, you receive a call from someone in your address book saved as a mom and speak for five minutes. Google detects some anxiety in your voice and confirms to us what it had already assumed: there is tension between you and your mother.
She had deduced it from several factors, including the large number of times you did not answer her calls even when you were at home, and the fact that during the holidays you are far from her and did not not call her.
Later, you take a selfie with friends and from the photo's metadata, Google can know where and when it was taken. By analyzing the image, he can identify the people represented as well as the type of clothing, from which he can deduce tastes and brands, useful to confirm things you already know about yours and their economic level.
Arrive in the evening and go running in the park listening to music and wearing an electronic bracelet that records your activities such as type of gait, heart rate, etc. You never noticed it, but the music streaming app and the bracelet app warned somewhere that the data would be shared with third parties, i.e. business partners. What you couldn't know is that Google is one of them, which therefore also knows your physiological data, your sports habits as well as your musical tastes.
Google also knows that you are a romantic and thoughtful person, because it comes out of what you are looking for online in free moments; knows that you are reading and have a penchant for pandas.
We can't say for sure which Google surveys are always running, which unique for "" purposes and what are the detections rather than technically it could do but in reality it does not work. We cannot say, because only Google knows what is happening on Google's servers, and because its tools are often closed and do not allow transparent verification.
Whatever surveys we do, we know that Google is watching us through countless channels and recording our activities. The sheer amount of data that Google has access to allows it to rebuild people's lives in a way that even a powerful and ubiquitous social network like Facebook cannot dream of.
2. We are a field of commercial conquest
When it comes to Big Tech, that is to say of the main technological multinationals, the first observation that ever in history, few private commercial companies of such colossal dimensions had managed to become an inextricable part of the life of billions of people , and so widespread and widespread.
Even more worrying is the already problematic scenario of some large companies holding power over technologies deemed essential. reverse factors of discovery: never before had every detail of the lives of billions of people been brought to such a level of commodification, to the point of being counted among the lands of conquest of a few colossal private companies.
So let's talk about big datathat is to say extracting detailed information from our activities, from ours vine, not just for commercial purposes.
That of big data a circuit that feeds on to constantly expand its margins. There is an unequal exchange between us, people / users and companies which, thanks to the data we provide, develop techniques and tools to link us more to them, to extract even more information from us.
This is done by known and less known technical and psychological solutions, design choices applied to software that uses gamification to encourage us to interact more or through the imposition of standards de facto from which it is very difficult to escape. The search for gratification given by likes or the possibility of giving up Whatsapp, for example.
Here we can observe the nourishing circuit: indiscriminately embracing the services and tools imposed by the technological industry is increasingly becoming a compulsory choice, because the more they are adopted, the less there is room for free alternatives: text documents are almost always made up of speech; to share work files in most cases, the choice almost always falls on Google Drive, Dropbox and little else; to know the activities of an association you have to be on Facebook; if you want to create an email account, the choice of providers is addressed to a limited number of giants (Google above all), etc.
With theInternet of things (now IoT), that is to say that with the increasing number of objects permanently connected, we will only extend the fields of destruction: electric cars that communicate in permanently a myriad of data, light bulbs that the company will know if they are on or off, hair dryers, televisions, refrigerators, bikes, kitchen utensils, wristwatches, etc. It is easy to envision the development of countless IoT technologies by medium and small businesses which will then be absorbed by the big giants, and it is not science fiction to imagine a near future in which it will be difficult, if not impossible, to obtain objects that do not transmit information to Big Tech.
This is the first problem: the more we use commercial tools and platforms, the more we exclude their independence.
Among the large companies that revolve around this massive data mining, the most impressive is certainly Google. Certainly not the only vampire company, and many of the comments in this article could also apply to others, the best known of which are part of the acronym GAFAM: Google, Apple, Facebook, Amazon and Microsoft. However, if each of these companies has evolved from specific sectors not necessarily focused on data mining, Google was born from the start as pure information receiver, and the one that over time has expanded its extraction capabilities in the most widespread and widespread manner.

–
3. "We know" but we don't know
That Google looks at us a common sentiment, but on closer inspection, it's a simple latent knowledge: we know that certain banner ads only appear after having carried out certain searches, and we are constantly reminded that cookies to access different sites are used to profile us, but apart from these few examples and from the general concept, variety escapes us and the functioning of the mechanisms by which data extraction occurs.
This is the second problem: in a society increasingly dependent on information technologies, the lack of knowledge of the functioning of these tools puts us more or less in the position of illiterates who must evolve in a world of more and more based on written language.
Unlike literacy, however, computerization can take place at much more diverse levels, and this is demonstrated by the fact that it is possible to be savvy users at the same time. that move easily between emails, spreadsheets, chat systems, smartphone settings. and applications of all kinds, but unable to write a single line of code and having no idea how these tools work.
Being users who know how to use the tools is not enough, because the lack of comprehension of them deep operation relegates us to the passive condition of simple end users, lacking the knowledge necessary to develop a critical approach so as not to be overwhelmed.
News appears periodically about personal data breaches, malicious apps, privacy issues, and disturbing episodes of Big Tech censorship and abuse of power. Yet despite all of these consistent signals in worrisome scenarios, the adoption of alternative tools has not yet become a widespread phenomenon. This is due to the two problems mentioned here: on the one hand the dominance of Big Tech products and on the other hand the fact that an insufficient knowledge of these tools prevents understanding really the dangers that this area entails.
However, the domination of Big Tech is by no means inevitable, but it will not be possible to limit the oppressive drifts of information technology without the effort of learning the most collective possible on their functioning.
We certainly cannot expect that we will all become programmers, nor that we will abandon radically and immediately known instruments and platforms in favor of free instruments that we do not know (yet) , but in any case, it is necessary to present yourself as quickly as possible and start right now a process of learning and adopting free technologies.
4. How could it have happened?
It is useful to briefly summarize the current situation. In the 1990s, the arrival of the Internet and the web was greeted by a cross-cutting and widespread wind of cyber-utopianism, often so enthusiastic that he was convinced that the extension of the network would bring automatically spontaneous computerization of the masses, and therefore forms of planetary democratization by technological means. This enthusiasm was born from the meeting between the utopian and anarchist visions prevalent among computer scientists, hackers and activists and from the naive curiosity of the majority of people towards technologies with a vaguely sci-fi flavor.
In the same years, the contrast between Microsoft and the GNU / Linux free operating systems already contained all future conflicts between large companies and free software: thanks to the commercial agreements concluded by Microsoft with the main manufacturers of software. computers around the world, when purchasing a new PC, as a Windows system was installed on it (and as we all know, this situation has continued to this day) . This is how the firepower of the company Redmond min radically adopted the GNU / Linux operating systems for personal use. Today Windows is actually the main standard for personal computers.
At the turn of the year 2000, the craze for new technologies led to the birth of experiments like that of Indymedia, but also to the explosion of the dot speculative bubble. -com, which has thwarted countless digital businesses. If the 90s had been characterized by a high rate of experimentation involving operating systems, online communication platforms, digital formats and different types of sites capable of being born and dying in very little time time, the Zero years have matured the previous experience with the birth of a large number of tools and business platforms whose fortune continues today.
Just to give a few well-known examples, in addition to reconfirming the already solid existing realities **, like Amazon (1994) and Google (1998), the zero years saw the birth of iTunes (2001), Wikipedia ( 2001), Skype (2003), Facebook (2004), Gmail (2004), Yelp (2004), YouTube (2005), Google Maps (2005), Twitter (2006), Google Docs (2006), Spotify (2006), Smartphone (2007 – first iPhone), DropBox (2007), Chrome (2008), AirBnB (2008), Zalando (2008) WhatsApp (2009), Uber (2009), Pinterest (2009), Instagram (2010), Tablet ( 2010 – first iPad).
Thanks to the increasing spread of the Internet and the continuous increase in online services, access to the Web has started to become a daily experience, even outside the workplace, for many people. who were not from the IT world or hacking.
If hacktivist environments envision a user future with a critical and active approach to IT, new business platforms understood that the real deal was extracting user information, and that it could be achieved by providing free and immediately functional tools, which required very little effort to figure out how to use them. Most of the users have therefore approached the Web during these years finding the availability of free applications and platforms made with large capitals, widely advertised, aesthetic and very easy to use. If, in the 90s, it was considered normal to have to pay for services such as email, now a whole generation of users has been educated to adopt free tools and services, and to consider the need to give access to their data in inevitable return.
The free software created by a heterogeneous galaxy of realities without large capitals, which required an effort of better understanding and in certain cases paying, was decidedly less attractive.
The result that over time, apart from a few worthwhile exceptions from the world of hacking itself, even the most critical and attentive environments have come to embrace the same business tools they should have objected to. . So we ended up with anti-capitalist realities who communicate their initiatives on Facebook, exchange emails with Gmail, communicate with Whatsapp and exchange documents with Google Drive.
Another worrying fact is that several public organizations have entrusted their communications (including internal!) To Big Tech tools. In addition to consolidating these worrying situations of private monopoly and contributing to the spread of data mining In our lives, the uncritical adoption of these means has helped to consolidate the misconception that this model of large capital company which provides centralized tools on a global scale is the only possible one.
5. Free software
One of the frustrating aspects of this massive use of tracking technologies is that there is no shortage of alternatives. Not only has he never stopped creating free software, but rather, it covers a large percentage of the software produced in the world.
Admittedly, it is not possible to condense in a few lines the nature, the philosophy and the history of free software, of the international movement which supports it and above all to expose its different facets, but just to To illustrate its essential characteristics, suffice it to say that these are programs whose code is open source and freely distributed. This allows anyone who has the opportunity to check its operation, collaborate to improve it, modify it and create alternative versions.
This is a significant difference from commercial software, which is rather closed, untouchable and protected by copyright. Wanting to make an automotive comparison, free software like a car whose hood you can open, see the engine, repair it, modify it or even assemble a new one, while the software closes like a car whose hood is sealed and you can only try to deduce how it works exactly, without ever being sure.
While commercial software is still controlled by the company that produces it, free software created and maintained by a range of realities that range from the single programmer who works independently to the ethical company that makes the software he created available for free, earning more from the sale of services or through donations, to entire communities dedicated to the collective development of a complete operating system.
The same philosophy with which free software is created stimulates constant reviews by entire global communities and often makes it much more efficient than commercial software, to the point that even many commercial tools that we use daily contain, under their hoods, enough portions of free software.
If on the one hand commercial companies imposed their domain through a firepower difficult to counter, on the other hand while being true that they also imposed themselves thanks to a certain type of Pay attention to the average user, in terms of simplicity and immediacy of use, which the world of free software has not always been able to provide.
However, this is also a classic recursive situation: the slightest adoption of free tools by the majority of users both causes and results from their insufficient adaptation to the needs of the general public. public.
An example may be above all the case of Jabber / XMPP, chat technology that has existed since 1999. It has nothing to envy of the different Whatsapp, iChat and others, but has never been able to impose itself. Most likely, a higher initial adoption would have greatly helped to consolidate its spread and encourage more people to take action to improve certain characteristics that further slow its spread.
It should be borne in mind that due to certain characteristics which can make the use of free software less immediate, there are often reasons have to be kept as such. Let's take the example of Jabber / XMPP: to use Whatsapp, Viber or Telegram in a few clicks on the smartphone and these, after taking possession of our phone number and all our contacts, work immediately. On the contrary, Jabber / XMPP requires the creation of an account then the contacts must be entered manually. If in the first case we give the data of all our knowledge and all our dialogues in exchange for an immediately functional tool, in the other we have a tool that requires some initial adjustments, but in return it doesn & # 39; Encroaches on anyone's privacy.
 In any case, the free software world has never looked and has constantly won and improved its attention to the average user. mastodon one of the examples of free software which, aiming to balance its complex functionality and its most simplified use, manages to attract large numbers.
In any case, the free software world has never looked and has constantly won and improved its attention to the average user. mastodon one of the examples of free software which, aiming to balance its complex functionality and its most simplified use, manages to attract large numbers.
6. The thousand tentacles of Google
Usually those who use a certain tool just want it to be easy and convenient to do what they should. This attitude may be sufficient in the case of tools which, by nature, have found themselves, such as a hammer, a bicycle or a typewriter, but it is no longer sufficient when it is These are computer tools, because these, under their visible part, they can behave in a way that we do not approve and which contribute to put us in a cage more and more.
In the case of Google, for example, the information that we actively insert into its tools is the part visible what we deliver: the texts we type: a word searched on the search engine, the content of an email, the appointments entered on the calendar, a city searched on Google Earth, but also the pdfs uploaded to Google Drive, photos and GPS tracks … This is data that anyone who realizes provides to the company.
But the part invisible the most consistent, made up of myriads of personal information that Google captures even when we don't even realize we're sending data, in fact, even when we don't even realize we're using Google.
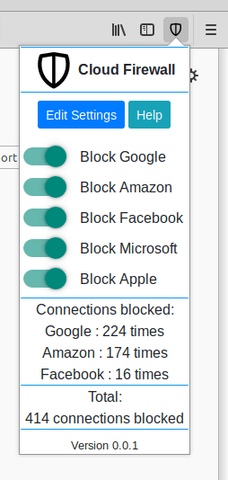 For example: when browsing a all website most likely it contains components that pass information to Google. A browser extension Firefox appointed Cloud firewall allows you to block these items. particularly instructive to browse the sites you visit regularly, but with Cloud Firewall configured to block all tracers or even those of Google: on some sites the banner ads disappear, in others the comments no longer appear, or the videos and images may disappear, or there are no longer the fonts or the usual backgrounds; several buttons disappear or stop working; some pages are no longer even navigable, because they are entirely based on Big Tech services. Just an afternoon of surfing with Cloud Firewall enabled to realize immediately how much part of the Internet is materially in the hands of these few companies.
For example: when browsing a all website most likely it contains components that pass information to Google. A browser extension Firefox appointed Cloud firewall allows you to block these items. particularly instructive to browse the sites you visit regularly, but with Cloud Firewall configured to block all tracers or even those of Google: on some sites the banner ads disappear, in others the comments no longer appear, or the videos and images may disappear, or there are no longer the fonts or the usual backgrounds; several buttons disappear or stop working; some pages are no longer even navigable, because they are entirely based on Big Tech services. Just an afternoon of surfing with Cloud Firewall enabled to realize immediately how much part of the Internet is materially in the hands of these few companies.
Mais cela ne s'arrête pas là: Google offre aux programmeurs, concepteurs de sites Web et divers professionnels une longue série de services techniques une liste disponible sur Wikipédia qui ne prête généralement pas beaucoup d'attention et avec lequel nous traitons quotidiennement, tels que les captchas (vérification en deux étapes pour accéder à un site Web), la connexion avec le compte Google ou Google Analytics. Ce sont tous des outils (tentacules) avec lesquels Google étend ses capacités d'extraction de données. Ceux qui utilisent Android synchronisent très probablement leurs contacts via Google, puis leur livrent l'intégralité de leur carnet d'adresses. Il existe des applications d'actualités qui s'appuient sur Google Actualités et fournissent donc des informations sur les sujets qui nous intéressent, etc. Certains de ces outils peuvent même être essentiels au fonctionnement d'Internet, comme le Google Public DNS, sur lequel il vaut la peine de passer quelques mots.
7. DNS public de Google
Chaque site Web identifié par son propre code unique appelé Adresse IP qui fonctionne plus ou moins comme un numéro de téléphone: entrez le code IP dans le navigateur et cela se connecte à la page souhaitée. Par exemple, ce message se trouve sur Giap, dont l'adresse IP 136.243.238.37. Si vous entrez cette adresse dans la barre de votre navigateur, appuyez sur Entrée pour ouvrir la vôtre Giap.
Les adresses IP sont gênantes à retenir: j'ai lu un super article sur 136.243.238.37 qui ne sonne pas très bien … Pour cette raison, depuis le début du web, un réseau de serveurs appelé DNS, Domain Name System, a été développé, chacun contenant un sorte de carnet d'adresses public qui connecte les adresses IP à des noms qui sont plus faciles à mémoriser, les noms de domaine, c'est-à-dire les URL auxquelles nous sommes habitués qui commencent par www et se terminent par quelque chose. grâce au DNS que nous pouvons utiliser www.wumingfoundation.com au lieu d'une séquence de chiffres inconfortable.
Voici la partie qui nous intéresse: lorsque nous tapons une URL ou cliquons sur un lien, notre appareil ne fait que rechercher un ou plusieurs serveurs DNS en leur demandant l'adresse IP correspondante et en autorisant la connexion. Il est clair que quiconque gère un serveur DNS saura toujours qu'un ordinateur ou un smartphone donné a recherché un certain site, et quel que soit le modèle d'ordinateur ou de téléphone utilisé, le système d'exploitation, le navigateur et le moteur de recherche. Eh bien, le plus grand service DNS est utilisé dans le monde et que nous trouvons facilement défini par défaut dans nos appareils il appartient à Google.
Google déclare supprimer une partie des données de navigation dont il a connaissance dans les 48 heures, mais qu'une autre partie les conserve indéfiniment. Fondamentalement, nous sommes confrontés à une entreprise qui, en plus d'avoir un quasi-monopole sur les recherches en ligne, a également le contrôle d'une grande partie des données de navigation, même pour ceux qui n'utilisent pas son moteur de recherche.
Eh bien, cela prend peu de temps pour changer le serveur DNS que notre appareil interroge par défaut.
8. Différentes sources mais analyse unique
Recherches en ligne, trafic DNS, mouvements de souris, positions GPS, réseaux auxquels vous vous connectez, annuaires téléphoniques, touches tapées au clavier: ce sont des informations de nature très différente, et prises individuellement, elles peuvent avoir une importance relative, mais toutes ensemble et en main pour une seule entreprise, ils peuvent être croisés et à ce stade, ils deviennent extrêmement importants (pour l'entreprise) et dangereux (pour nous).
Per esempio, durante una banale navigazione in Internet le diverse fonti a cui Google attinge permettono di ricostruire ogni minimo dettaglio della nostra navigazione: possiamo fare una ricerca su Google (1) che ci rimanda a un sito che contiene componenti di Google (2), banner pubblicitari di Google (3) e un video di YouTube (4). Per accedere al sito potremmo doverci loggare con l’account di Google (5) e passare per il suo captcha (6). All’interno poi troveremo un link ad un secondo sito e cliccandoci useremo il DNS di Google (7). Tutto questo potrebbe esser stato fatto con Chrome (8) da un cellulare Android (9) della linea Pixel (10), prodotta dallo stesso Google. Pi sono gli strumenti di Google che utilizziamo e pi dettagliata sar la sua conoscenza delle nostre attivit.

inevitabile che alcune attivit online vengano tracciate dai fornitori di servizi; ecco perch oltre alla comprensione degli strumenti e allutilizzo delle alternative libere, anche recidere i diversi tentacoli di importanza fondamentale, poich laccumulazione centralizzata di una grande mole di dati non permette solamente di ricostruire reti di contatti, abitudini e spostamenti ma, come si gi accennato, pu spingersi ancor pi a fondo permettendo una schedatura sociale, economica, psicologica e politica di ogni soggetto.
Qui si apre un campo di discussione vastissimo in cui l’analisi dei dati va a toccare aspetti tecnici, semantici, psicologici, comportamentali, sociali e in cui strumenti e formule vengono continuamente sperimentati, scartati, modificati ed affinati. Le modalit e i criteri con cui questi dati vengono analizzati non sono di pubblico dominio e al massimo possiamo presumerli o dedurli.
Chi presta attenzione alle notizie tecnologiche sa bene che negli anni Google ha continuamente sviluppato e acquistato aziende che producono strumenti di vario genere utili ad acquisire pi informazioni o analizzarle con maggior dettaglio, e che tra il personale di Google vi sono psicologi, sociologi, esperti di statistica e di altri campi grazie ai quali vengono sviluppati algoritmi di analisi sempre pi raffinati, capaci di dedurre statisticamente tendenze sopite e debolezze psicologiche di ogni singolo utente arrivando a stilarne un ritratto completo e dedurne la forma mentis. E non solo la nostra: anche quelle di chi fa parte della nostra rete sociale.
Ci significa che liberarsi dagli strumenti di Google non sufficiente se viene fatto da un singolo utente, senza coinvolgere anche gli altri componenti delle nostre cerchie sociali: Google saprebbe comunque chi ti ha inserito in rubrica e chi ti chiama dal proprio telefono Android, saprebbe il tuo compleanno perch altri lo hanno inserito nei loro calendari e saprebbe quando la tua solita compagnia si trova tutta assieme nel vostro locale preferito grazie ai loro GPS ecc.
Google potrebbe anche condurre esperimenti mirati, come far funzionare appositamente male l’assistente vocale in determinati momenti solo per misurare l’ansia e nervosismo che questo genera in noi, analizzando la nostra voce, oppure esponendo gli abitanti di regioni diverse a versioni differenti di una stessa notizia per studiarne le reazioni. Le tecnologie dell’informazione in mano a societ di capitali, dunque, non si limitano a trasformare il mondo in una rete di sorveglianza a cielo aperto, ma trasformano ogni persona in una cavia per esperimenti psicologici e sociali e rendono amici, parenti e vicini delatori involontari, fonti di informazioni su di noi.
9. Il problema non sono necessariamente i dati, ma chi li detiene e ci che vuol farne
Google guadagna dalla vendita dei nostri dati. O meglio: vende aggregazioni e analisi dei nostri dati. Quali siano i dati che vende dipende da scelte commerciali e, almeno in teoria, da limiti legali. In teoria, non pu vendere dati sensibili capaci di ricondurre gli acquirenti alla singola persona, ma quali siano esattamente questi limiti argomento tecnico-giuridico assai complesso: ad esempio, vendere anonimi tracciati GPS di percorsi fatti al mattino in bicicletta da attiviste napoletane di sinistra tra i 25 e 30 anni con un debole per i panda, potrebbe essere perfettamente legale.
Che siano venduti o no, tuttavia, questi dati sono comunque informazioni presenti nei database di un’azienda privata che in futuro potrebbe analizzarli con nuovi strumenti, venderli legalmente, farseli rubare o essere obbligata a comunicarli a governi e agenzie di intelligence. Gi ci sono segnali in questo senso: il governo degli Stati Uniti ha tentato di imporre ad Apple di fornirgli gli strumenti per poter accedere a qualunque iPhone, generando l’assurda situazione in cui una multinazionale si atteggiata a paladina “buona” della privacy.
La cessione di questi dati e analisi ad aziende private o enti di sorveglianza pu portare a scenari che non esagerato definire distopici. Solitamente, chi difende questo stato delle cose o minimizza il problema se ne esce con la massima fascistoide secondo cui chi non ha nulla da nascondere non dovrebbe preoccuparsi, non facendo altro che deviare il discorso dal punto della questione: il problema non necessariamente il contenuto dei dati di per s, ma chi li detiene e ci che vuol farne!
La consegna di tutti i nostri dati permette di redigere profilazioni che per quanto raffinate esse siano, non escludono mai i bias di chi li realizza. In sostanza, chi ritiene di non aver nulla da nascondere non fa che affidare il giudizio sulla propria intimit a multinazionali e poteri governativi, che ovviamente la giudicheranno coi propri parametri culturali e in base ai loro interessi.
Tu che leggi sei una persona “irreprensibile”? Poco importa: gli scenari che potresti incontrare in un futuro caratterizzato da un uso ancor pi massiccio dei big data sono comunque tremendi. Le scuole migliori (privatizzate) potrebbero rifiutare l’iscrizione dei figli perch in base alle analisi preventive effettuate tramite big data non rientrano nei loro standard; enti di polizia potrebbero metterti in una lista di “attenzionati” perch classificano come pericoloso chiunque legga un determinato sito nonostante contenga contenuti legittimi; la tua compagnia di assicurazioni potrebbero aumentarti la polizza in base ai dati fisiologici ottenuti dai tuoi attrezzi sportivi; aziende potrebbero negarti l’assunzione perch nella tua rete di contatti vi sono sindacalisti a loro non graditi, e cos via.
Sono scenari potenziali, si, ma che si trovano dietro l’angolo: a dividerci da loro ci sono forse alcune reticenze e barriere legali, ma in questa direzione che il capitalismo spinge con forza, ed un futuro che pu tentare di realizzarsi in diversi modi: abituando le persone a consegnare volontariamente i propri dati, oppure per vie legali o in altre forme ancora, pertanto ogni segnale che punti in quella direzione va tenuto sott’occhio. In quest’emergenza coronavirus, ne abbiamo notati parecchi.
10. Decentrare, federare, adottare standard aperti
Liberarsi dalle maglie di Google e limitarne lo strapotere un processo che pu essere attuato solo adottando software libero, ma sostituire strumenti su cui non abbiamo il controllo con strumenti trasparenti non basta ad evitare la formazione di nuovi enti accentratori. Questo perch numerosi strumenti si appoggiano a servizi forniti da terzi: allo stato attuale, irrealistico prospettare uno scenario in cui ogni singola persona/utente gestisce da s un proprio server casalingo su cui girino chat, email o quantaltro.
Parimenti, lo scenario non meno irrealistico in cui diversi servizi globali siano sostituiti da una moltitudine di alternative indipendenti farebbe venir meno diversi dei vantaggi che offrono alcune piattaforme globali.
La soluzione prospettata da diverse piattaforme libere per fornire al tempo stesso i vantaggi delle reti autonome e la comodit delle grandi piattaforme consiste nellapplicazione di due concetti: decentralizzazione and federazione, con cui si intende la creazione di reti interconnesse tra loro (federate) di diversi fornitori di servizio indipendenti (decentralizzati) attraverso una tecnologia di comunicazione comune.
Un esempio di strumento federato e decentralizzato gi noto e usato da anni lemail: gli indirizzi di qualsiasi provider difatti possono dialogare con tutti gli altri indirizzi mail esistenti.
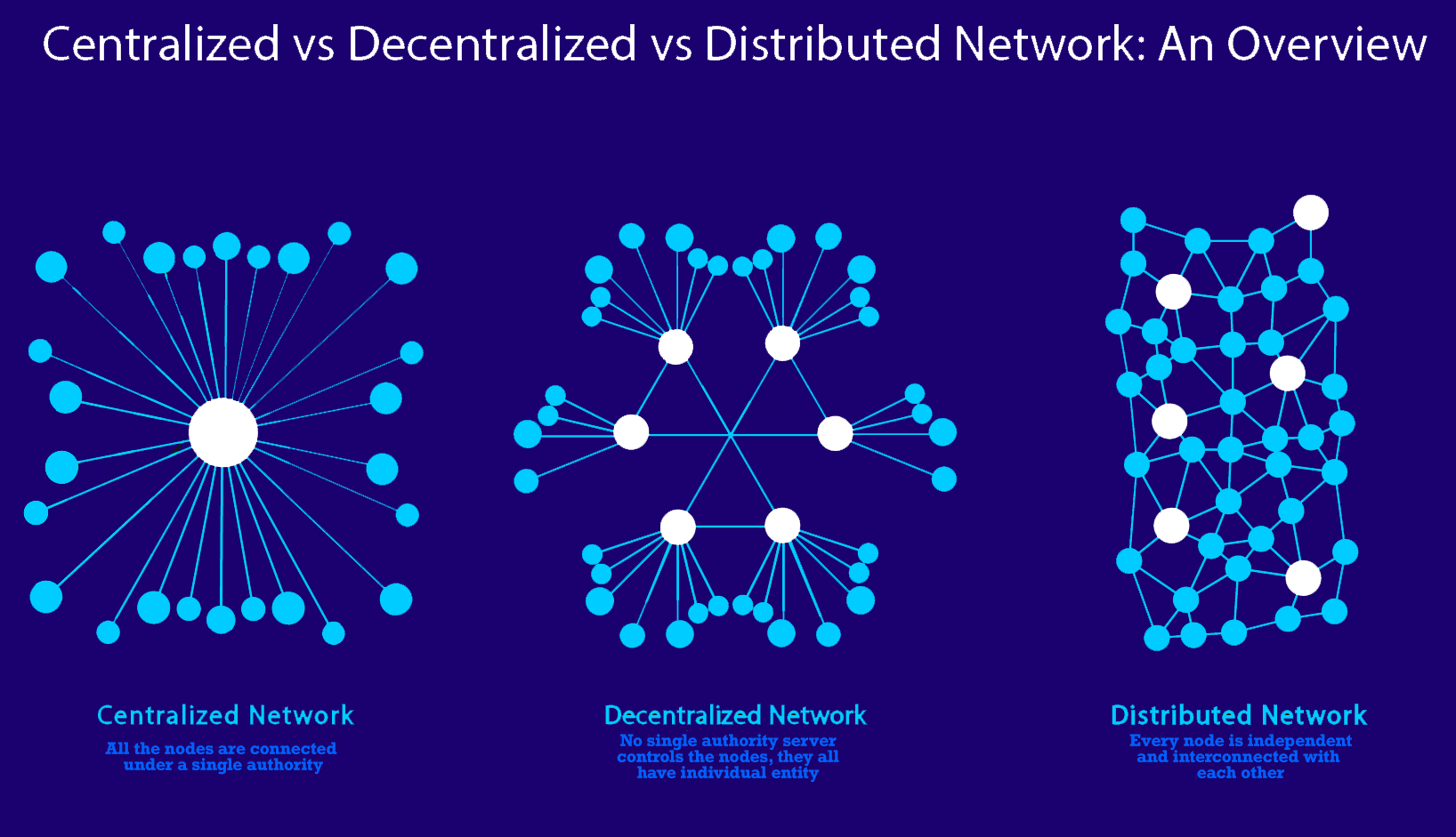
Il concetto di fondo consiste nel dare la priorit non a singoli strumenti alternativi ma a protocolli aperti che possano a loro volta essere utilizzati tramite strumenti liberi, ossia consolidare standard diffusi e utilizzabili da chiunque senza obbligare nessuno a legarsi ad un certo fornitore di servizi specifico
Per fare un paragone: Whatsapp uno strumento chiuso che pu essere usato esclusivamente passando da Whatsapp stesso (se ti togli da Whatsapp perdi tutte le chat Whatsapp); al contrario Mastodon uno strumento aperto privo di un “centro di comando”, che permette a chiunque di crearsi il proprio server con le regole che preferisce.
Lo stesso concetto pu essere applicato in diverse forme: scegliere ad esempio di sostituire Google Drive passando in massa a Dropbox aiuterebbe ben poco. Al contrario si pu scegliere uno dei numerosi provider che usano il software libero Nextcloud: anche qui, lo stesso software, ma messo a disposizione da realt diverse e indipendenti fra loro.
La preferenza per gli standard aperti pu essere declinata anche sui singoli file: ognuno, ad esempio, pu scegliere leditor di testi che preferisce ma se ci si impone di usare solo editor che possano lavorare in formato .odt (Opendocument, lalternativa libera dei file .doc) ecco che ci porterebbe pure diverse aziende commerciali ad adottare standard aperti.
dunque possibile passare da una situazione che vede un servizio di Google impostosi come riferimento unico globale, tipo Google Maps, ad una situazione con applicazioni diversissime e indipendenti che hanno come riferimento comune le ricche mappe di OpenStreetMap.
Si tenga anche conto che in alcuni casi ci pu richiedere un acquisto o una donazione, perch realizzare e mantenere certi servizi pu avere un certo costo.
11. Propaganda invisibile e mirata
Il banner “targetizzato” che appare dopo che abbiamo fatto una certa ricerca, per quanto fastidiosissimo, solo la forma pi grossolana e visibile di utilizzo dei nostri dati a scopo propagandistico-commerciale.
Le cose diventano molto pi ambigue quando la propaganda si manifesta in modi meno espliciti. Gi adesso, per intenderci, Google cambia da utente a utente lordine dei risultati che mostra sul suo motore di ricerca, ma nei possibili sviluppi futuri delle tecnologie che coinvolgono le intelligenze artificiali (IA) che il quadro si fa pi inquietante. I testi scritti automaticamente dalle IA. si stanno facendo sempre pi indistinguibili da quelli realizzati da esseri umani ed dunque possibile prospettare che dei crawler programmi automatizzati che scrutano i contenuti presenti in rete collegati ai database di Google e a IA specializzate in scrittura, potranno di fatto essere utilizzati come giornalisti-robot capaci di generare in tempi rapidissimi articoli di news altamente targetizzati, coi quali sarebbe possibile propagandare una stessa informazione in modi differenziati, per far passare un medesimo concetto a persone di orientamenti totalmente opposti, differenziando gli articoli in forme adatte ad essere maggiormente accettate da ciascun singolo utente.
Se il concetto da far passare fosse che il soggetto politico X inaffidabile, a una stessa ricerca le persone gi ostili a tale soggetto potrebbero vedere notizie che rafforzano la loro avversione, mentre alle persone simpatizzanti le stesse notizie potrebbero essere mostrate in forme pi ambigue e sfumate, in modo da scavalcare le difese e generare comunque sospetti e dubbi.
La colonizzazione dei quotidiani da parte delle aziende di data mining potrebbe avvenire in forme non dissimili da quelle gi applicate dalla gig economy in altri settori: cos come AirBnB non “possiede” gli appartamenti che affitta, Google potrebbe non possedere mai i quotidiani, ma legandoli irrimediabilmente a s attraverso i propri servizi e detenendo il potere sulle piattaforme utilizzati, controllarli di fatto. Attualmente Google avvantaggia i siti di news che adottano un suo formato di pubblicazione chiamato AMP, legando cos a s queste testate, spingendoci a preferirle rispetto ad altre. Se cerchi una notizia su Google vengono mostrate prima le testate che usano AMP, mentre articoli forse pi completi e documentati vengono relegati alla pagina 3, che raramente viene aperta.
Nel caso di Cambridge Analytica, che ha riguardato la Brexit e le presidenziali statunitensi del 2016, stato osservato che il massiccio uso di news dal taglio personalizzato e distribuite nei feed personali di Facebook pu aver influenzato l’opinione pubblica in maniera rilevante ma non controllabile, mostrando contenuti di propaganda mirata di cui non stato possibile tenere traccia, dato che scomparivano poco dopo esser stati letti (Facebook non registra la cronologia di quali annunci vengono mostrati ad un utente). In quel caso si trattato perlopi di post a pagamento che gli utenti pi sgamati avrebbero potuto identificare per ci che erano, ma cosa succeder quando non sar pi possibile comprendere se una data notizia targetizzata su di me o no?
Oggi la cosa viene ancora svolta con un alto tasso di intervento umano, tramite persone che si occupano materialmente di scrivere materiale di propaganda in seguito trasmesso da bot o pubblicato come annuncio a pagamento ma non cos distante il futuro in cui potremmo interagire con bot indistinguibili da utenti reali, con tanto di voce e immagine video generata artificialmente, che dialogheranno con noi esponendoci le loro “opinioni” utilizzando sottigliezze discorsive e psicologiche tagliate apposta per far breccia nella nostra psiche, grazie al fatto che, a nostra insaputa, ci conoscono perfettamente.
Propaganda commerciale e propaganda politica si rivelano di fatto indistinguibili e ci non un mero accidente causato dalla tecnologia: si tratta della naturale evoluzione delle logiche capitalistiche, che vedono nell’estrazione di valore dalle attivit umane la premessa per manifestarsi appieno nella loro evoluzione successiva, ossia il capitalismo della sorveglianza.
12. Capitalismo della sorveglianza
Il capitalismo della sorveglianza gi realt. Semplicemente, le forme in cui si realizza non si sono ancora espresse al massimo. E se le sue manifestazioni materiali pi evidenti sono quelle legate all’IoT, soprattutto agli aspetti sociali derivanti dalla loro implementazione che bisogna prestare attenzione, e soprattutto alla domanda di sicurezza che oggi viene costantemente alimentata (c’ sempre un’emergenza utile alla bisogna).
Basta solo ipotizzare che le reti di telecamere gi esistenti nelle nostre citt vengano implementate come sta avvenendo in altre parti del mondo con tecnologie di riconoscimento facciale a loro volta connesse con profilazioni ottenute da fonti come Google, per rendersi conto del potenziale livello di controllo a cui andiamo incontro.
Tutto ci pu gi essere osservato in Cina, dove le tecnologie per la sorveglianza sono utilizzate in maniera massiccia: a Shanghai, megaschermi collegati a sistemi di riconoscimento facciale posti nei pressi di passaggi pedonali, mostrano il documento d’identit di chi attraversa con il rosso. Una forma moderna di gogna pubblica.

Le stesse tecnologie vengono impiegate in banche, aeroporti, alberghi e bagni pubblici. Se ne vedono le applicazioni pi estreme nello Xingjiang, dove tra sistemi di riconoscimento facciale, scansioni biometriche e sistemi di sorveglianza a terra ed aerea (coi droni) la regione abitata dalla minoranza uigura diventata un vero e proprio carcere a cielo aperto in cui i movimenti di ogni persona sono monitorati, registrati e analizzati.
la domanda di sicurezza di cui sopra, che da tempo plasma la vita nelle nostre citt, tra richieste di installazione di videocamere ovunque, militari impegnati nell’operazione Strade sicure, controlli di vicinato, droni che sorvolano le manifestazioni, sistemi di riconoscimento veicolare e accessi monitorati mostra tendenze che potrebbero evolversi in scenari non dissimili da quello appena descritto per lo Xingjiang. Lesempio pi recente cui abbiamo assistito stato quello dei lockdown imposti per il Covid-19, di dubbia utilit per lo scopo esplicito (contenere la diffusione del virus) ma utili a quello implicito, ossia far avanzare di qualche passo l’accettazione di controlli autoritari e sospensione delle libert.
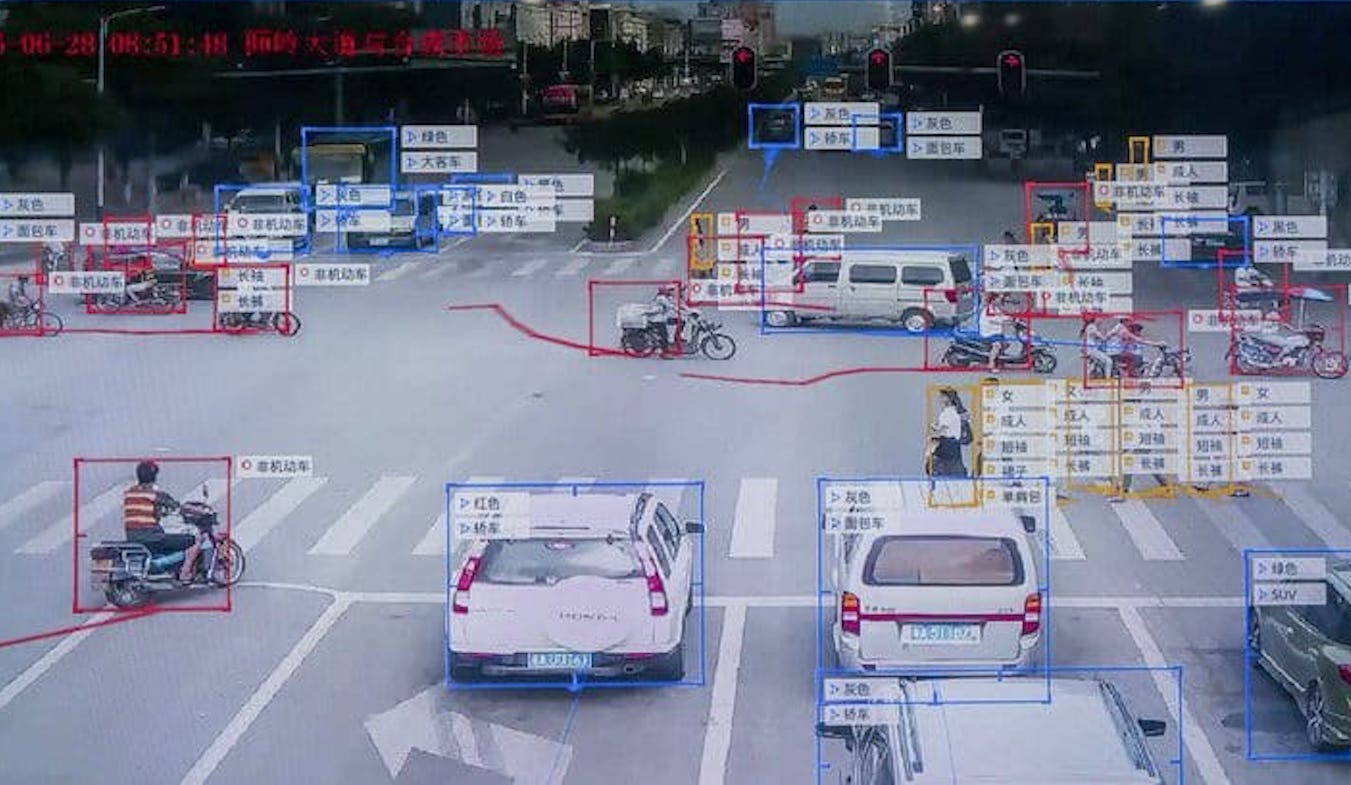
Non si tratta di scenari unilateralmente calati dall’alto: sono accolti e addirittura auspicati da una fetta della popolazione intrisa di ideologia securitaria o, pi spesso, auspicati parzialmente, senza rendersi conto dello scenario nel suo complesso.
Ci avviene nella presunzione che un monitoraggio costante di ogni attivit umana e sociale serva a renderci non solo pi sicuri ma pure pi efficienti, in una continua ricerca di ottimizzazione tramite sorveglianza e punizione.
Basta pensare al livello di controllo che diverse aziende applicano sui propri dipendenti, sempre pi spesso obbligati a registrare ogni loro minima attivit, a strisciare il badge allentrata e alluscita del gabinetto perch qualcuno possa stilare statistiche sui tempi della nostra pisciata media ecc.
Ecco, in soldoni, la peggior deriva a cui stiamo andando incontro: un futuro che gi qui, in cui raccolta di dati, profilazione, monitoraggio e sorveglianza senza limite sono legati a doppio filo con l’ideologia legalitario-securitaria diffusa nella societ social-mediatizzata.
13. Degooglizziamo le nostre vite
in riferimento a tutto questo che risulta interessante, utile e preziosa la campagna di degooglizzazione, che invita a non consegnare pi a Google nessun momento delle nostre vite. Si tratta di una campagna informale portata avanti in modo spontaneo, singolarmente o in gruppo, da un gran numero di hacktivist in tutto il mondo.
Rispetto ad altri processi simili e altrettanto importanti ma pi semplici da avviare come l’adozione di piattaforme alternative a Facebook, Instagram, Twitter e Whatsapp la rimozione di Google, per via della vastit e variet di campi informatici che tocca, una pratica da svolgersi in pi fasi, toccando ogni volta con mano e imparando tutti gli aspetti tecnici che necessario conoscere.
La degooglizzazione, in sostanza, aiuta ad allenarsi per portare avanti l’impegno, sempre pi necessario, a sviluppare una maggior consapevolezza informatica.
Una fonte consigliabile Framasoft, associazione francese nata per diffondere l’adozione di software libero. Da alcuni anni Framasoft porta avanti un progetto di degooglizzazione offrendo molti strumenti alternativi e suggerimenti utili.
Leggi: Cosa puoi fare nel 2020 insieme a Framasoft.

Conclusione
Siamo gi in ritardo e bisogna recuperare il tempo perduto. Si tratta di un percorso a volte scomodo la degooglizzazione non un pranzo di gala, ha scritto Wu Ming su Bida tempo fa ma la cui necessit sempre pi impellente.
L’impegno devessere il pi attivo, diffuso e collettivo possibile: esistono decine di hacklab e migliaia di persone capaci di aiutare in questo percorso, che ha perlomeno il vantaggio di poter essere effettuato a scaglioni:
sostituire il motore di ricerca di Google con DuckDuckGo and SearX operazione che si fa in un attimo;
sostituire Google Maps con OsmAnd o Pocket Earth pure;
stessa cosa per passare da Chrome a Firefox;
per aprire una nuova casella email con Autistici o Tutanota gradita una donazione, nel primo caso, o richiesto un piccolo pagamento, nel secondo;
per cose pi complesse, come passare da Windows a una distribuzione GNU/Linux o altro, ci vuole un po di pi tempo, via via fino a cose pi complesse come sostituire il sistema operativo del cellulare.
Seguire le news tecnologiche e i forum di informatica dovrebbe diventare unattivit costante. Inevitabilmente ci saranno scazzi, si sbatter il muso sul bisogno di cambiare abitudini, imparare l’uso di strumenti nuovi, aver a che fare con le diverse opinioni degli “smanettoni” su quale sia lo strumento alternativo migliore, ma il punto tirarsi su le maniche e cominciare a lavorarci.
Subito.
_
* Ca_Gi collabora a vari progetti della Wu Ming Foundation, tra i quali il gruppo di lavoro Nicoletta Bourbaki. Ha un blog dove pubblica tutorial tecnologici e controinchieste su vari temi, e un account sull’istanza Bida di Mastodon. Da mesi lavora indefessamente al proprio degoogling. Diamogli una mano, degooglizzandoci anche noi.
ALTRE LETTURE
Il 7 febbraio scorso Bruce Hahne, ingegnere e manager presso Google, si dimesso dallazienda con una dettagliata lettera aperta e lavvio di una campagna rivolta tanto agli altri lavoratori di Alphabet quanto all’utenza. L’accusa, documentata, di complicit nel disastro climatico e nel business della guerra. Per capirci, il precedente storico che cita il ruolo che ebbe lIBM nello sterminio nazista. Parla anche delle ritorsioni contro dipendenti gay e transgender, licenziat* per il loro attivismo dentro lazienda.
** Si noti che la maggior parte delle aziende nate negli anni ’90 inizieranno a diventare economicamente rilevanti solo dopo diversi anni dalla fondazione, a riprova dellimpegno economico-finanziario di chi, in anticipo sui tempi, aveva intuito la necessit di conquistare posizioni dominanti in questo settore. Il caso pi noto quello di Amazon che, sopravvissuta alla bolla delle dot-com, oper in perdita fino al 2001.
What Are The Main Benefits Of Comparing Car Insurance Quotes Online
LOS ANGELES, CA / ACCESSWIRE / June 24, 2020, / Compare-autoinsurance.Org has launched a new blog post that presents the main benefits of comparing multiple car insurance quotes. For more info and free online quotes, please visit https://compare-autoinsurance.Org/the-advantages-of-comparing-prices-with-car-insurance-quotes-online/ The modern society has numerous technological advantages. One important advantage is the speed at which information is sent and received. With the help of the internet, the shopping habits of many persons have drastically changed. The car insurance industry hasn't remained untouched by these changes. On the internet, drivers can compare insurance prices and find out which sellers have the best offers. View photos The advantages of comparing online car insurance quotes are the following: Online quotes can be obtained from anywhere and at any time. Unlike physical insurance agencies, websites don't have a specific schedule and they are available at any time. Drivers that have busy working schedules, can compare quotes from anywhere and at any time, even at midnight. Multiple choices. Almost all insurance providers, no matter if they are well-known brands or just local insurers, have an online presence. Online quotes will allow policyholders the chance to discover multiple insurance companies and check their prices. Drivers are no longer required to get quotes from just a few known insurance companies. Also, local and regional insurers can provide lower insurance rates for the same services. Accurate insurance estimates. Online quotes can only be accurate if the customers provide accurate and real info about their car models and driving history. Lying about past driving incidents can make the price estimates to be lower, but when dealing with an insurance company lying to them is useless. Usually, insurance companies will do research about a potential customer before granting him coverage. Online quotes can be sorted easily. Although drivers are recommended to not choose a policy just based on its price, drivers can easily sort quotes by insurance price. Using brokerage websites will allow drivers to get quotes from multiple insurers, thus making the comparison faster and easier. For additional info, money-saving tips, and free car insurance quotes, visit https://compare-autoinsurance.Org/ Compare-autoinsurance.Org is an online provider of life, home, health, and auto insurance quotes. This website is unique because it does not simply stick to one kind of insurance provider, but brings the clients the best deals from many different online insurance carriers. In this way, clients have access to offers from multiple carriers all in one place: this website. On this site, customers have access to quotes for insurance plans from various agencies, such as local or nationwide agencies, brand names insurance companies, etc. "Online quotes can easily help drivers obtain better car insurance deals. All they have to do is to complete an online form with accurate and real info, then compare prices", said Russell Rabichev, Marketing Director of Internet Marketing Company. CONTACT: Company Name: Internet Marketing CompanyPerson for contact Name: Gurgu CPhone Number: (818) 359-3898Email: [email protected]: https://compare-autoinsurance.Org/ SOURCE: Compare-autoinsurance.Org View source version on accesswire.Com:https://www.Accesswire.Com/595055/What-Are-The-Main-Benefits-Of-Comparing-Car-Insurance-Quotes-Online View photos
picture credit
 |
 |
 |
7 Comments